“将无同”&“桃源学境”是一个专注于文言文情境化学习的AI教育平台,旨在通过互动学习、AI辅助帮助中学生掌握文言文知识、热爱文化。我们希望“桃源学境”连接素质拓展+应试考试,每个学生都能拥有一个接近“复旦附中”老师水平的助教。
为什么是文言文?宏观层面,高考加强对文言文的重视。高考新课标(2020年修订)将“加强中华优秀传统文化教育”作为重点之一;推荐篇目数量也从14篇(首)增加到72篇(首)。应试上,文言文是除了作文以外最能提分的部分。许多一线高中语文教师和我们说,高三最重要的提分就在文言文。
现有的教育产品的不足?主要集中在两个方面。1.趣味性/情境性。传统文言文学习枯燥。古人生活离学生较远,没有切身的情境体会。纸质练习册也无即时成就感反馈。2.专业性。LLM在处理文言文任务其实多有错误,学界评测正确率仅67%(丘子靓,2025),如果没有优化处理,则很容易给予错误的知识。
学习环节
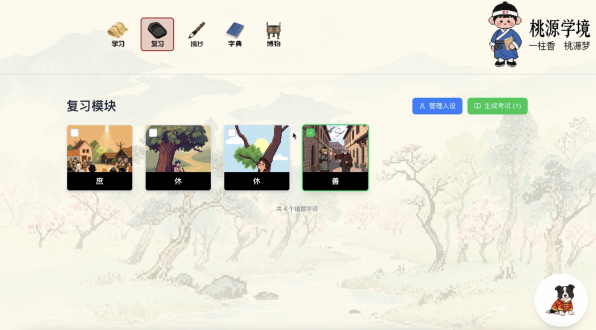
复习环节
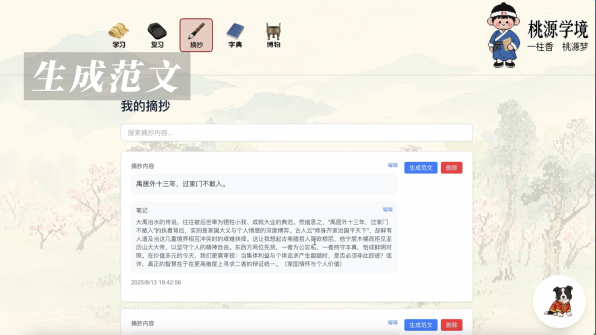
摘抄环节
伴学环节
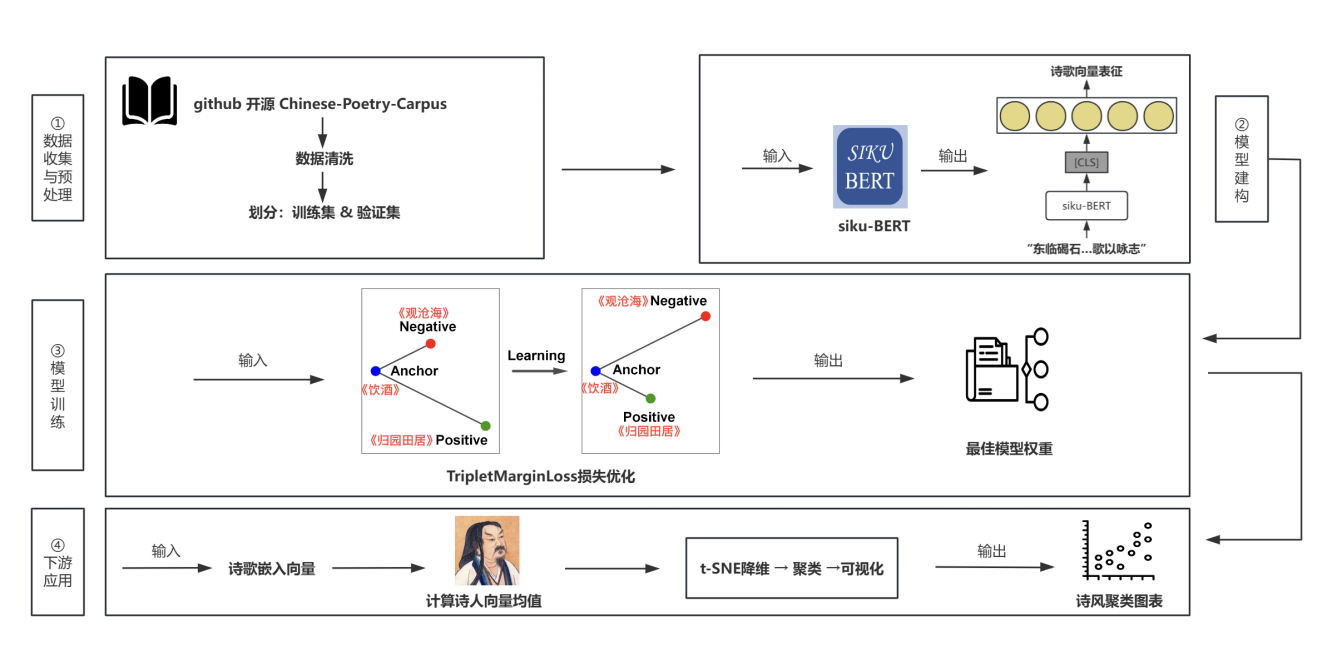
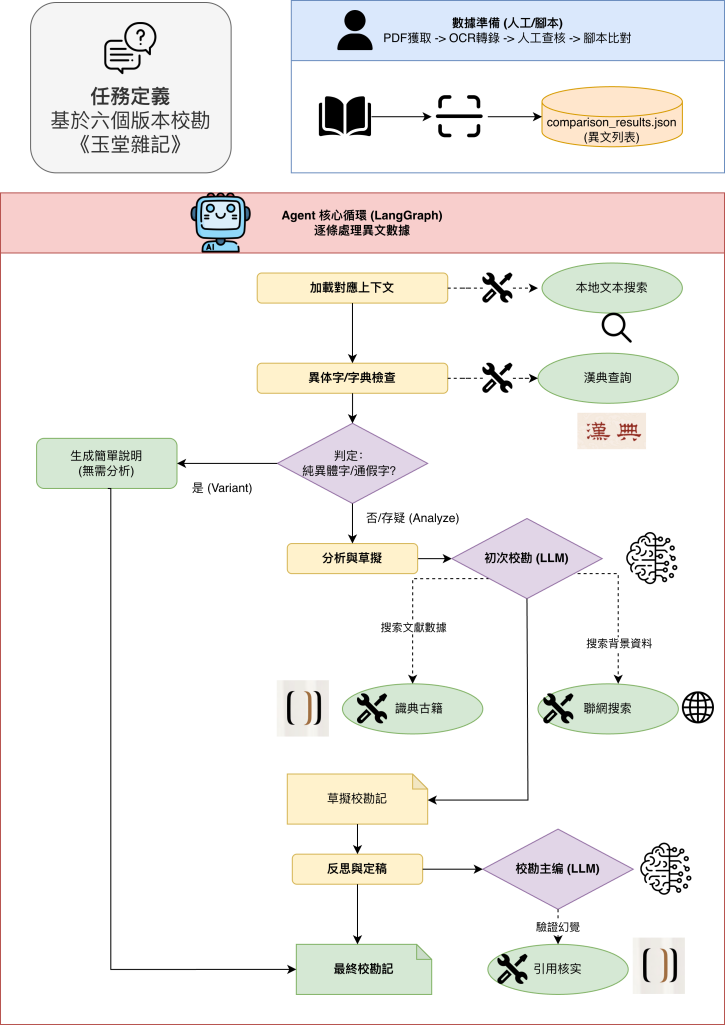
以往的教育产品中,核心学习内容均由人工建构。搭建AI+文言文工作流程,不能避免的是幻觉问题,什么时候能让AI来做,什么时候不能。“桃源学境”的古汉语字典、考情分析是专家构建的数据集,用以AI检索,有效消除幻觉。我们依旧要考虑的核心问题是:AI是否能胜任该工作?如果不能的话,能经过优化调节让其做到吗?
在主流学界和业界,优化AI表现的常用方法,主要有Prompt Engineering、RAG、Fine-tuning等。本项目我们主要运用Prompt Engineering和RAG,花了大量的时间,对ocr、标注、考试、范文的四部分AI表现分别进行评测,使之符合预期。比如在AI对文言文遇到的好句子写的高考范文,我们组织了12位评测专家,让他们对这30段文本打分(1-100分),这些专家全部来自于中文系,包含5位本科生、2位硕士生、2位博士生、3位一线教师。经过我们精心迭代的指令,AI范文不仅仅AI味显著减少,而且比人类范文还要好。
随后,我们在78名中学生中开展了一项被试内教育对照实验,对比该平台与传统纸质材料对文言字词的即时学习效果和长期记忆保持差异。实证结果显示,AI情境化平台能显著提升学生的短期学习效率,并在一周后的后测中展现出统计学意义上的更高记忆固化水平。
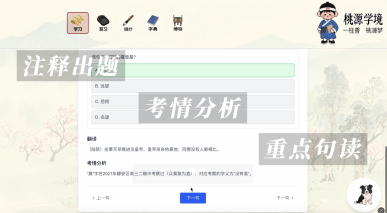
网站主要定义了四大情境:学习环节、复习环节、摘抄环节、伴学环节。当学生进入“学习”的时候,可以通过拍照上传文言文习题,视觉模型OCR结果,或者“随机造梦”。从后台随机挑选一篇文言文选段,进入学习环境。后台接受到这个文言文段落之后,会按照工作流程,依次生成内容概括;对其进行分句并且注释;标注是否为重点句,如若“是”则生成考题;判断高考模考真题是否涉及过这个字词,如若“是”则列出考情分析;最后生成这段话的相关图片与视频。在生成完成后,学生能够进入平台逐句学习、练习。回答错误时,对应考点会自动归类到错题本中,后台根据这个错字,生成对应的卡片。